Support Vector Machines
What are support vector machines? It is a supervised learning framework.First of all, what are support vectors? They are a subset of training points in the decision function. They are called support vectors.
What does it mean that different Kernel functions can be specified for the decision function?
What is a Kernel?
Note that we follow the https://scikit-learn.org/stable/modules/svm.html# page for content. We will add AIMA 18.6 and 18.9 as well.


1.4.1. Classification
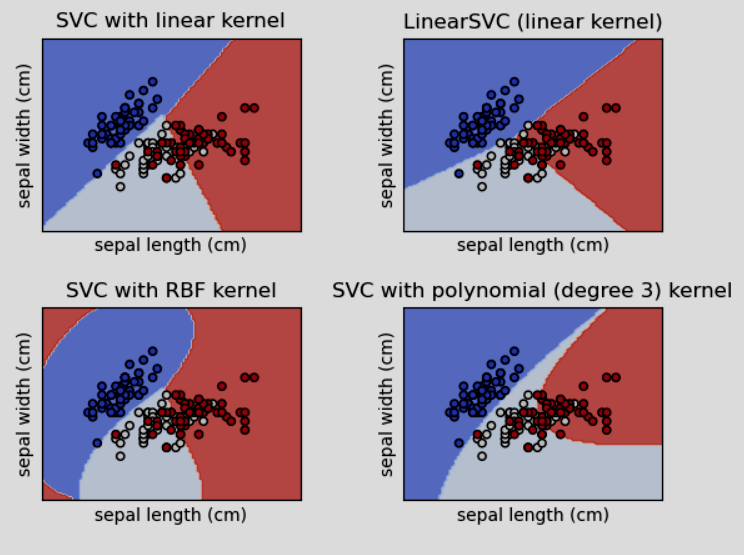
SVC, NuSVC, LinearSVC...
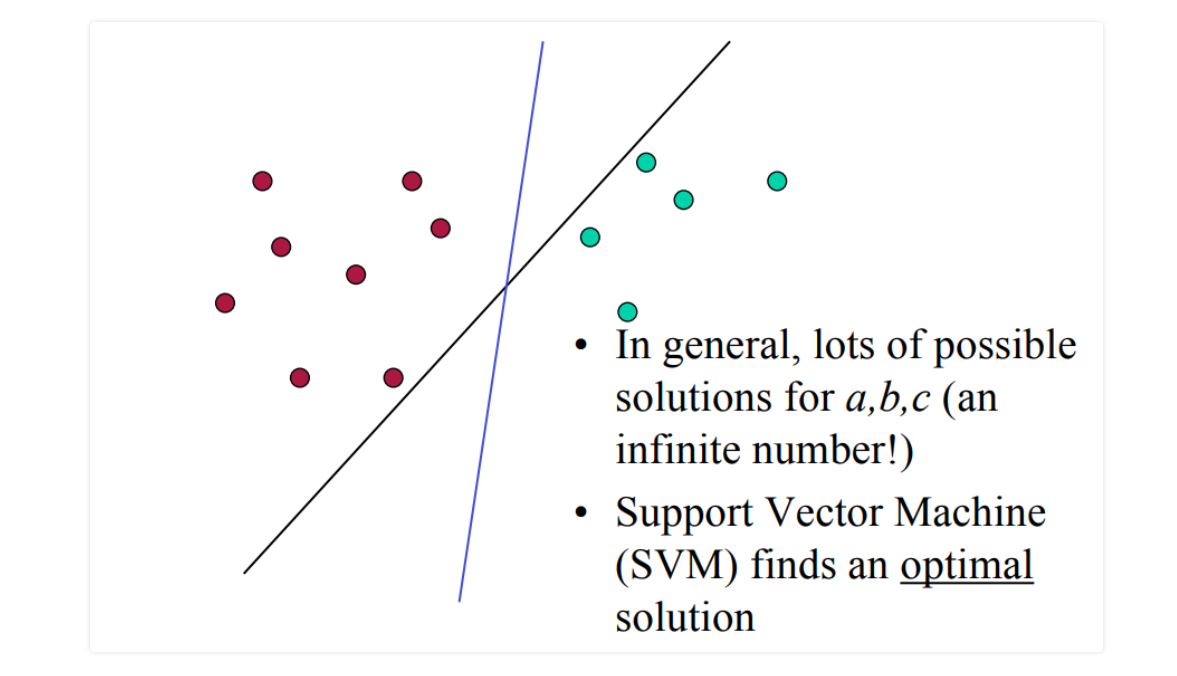 Support vector machines finds an optimal seperation of the data. Either linear or non-linearly. Obviously, nonlinearly it is harder.
Support vector machines finds an optimal seperation of the data. Either linear or non-linearly. Obviously, nonlinearly it is harder.margin = min(P, K)
where P and K are the distances to the separation line of data points belonging to two different classes.SVM trying to maximize the margin around the hyperplane. It means it tries to optimize the distance from the data points (support vectors) around the hyperplane. It is a maximization problem. We can use Lagrangian multipliers (always!) when there is a maximization problem and some possible constraints.
2D-case
Hyperplane is defined by (a,b,c) coefficient where,(1) ax+by-c>=0
(2) ax+by-c=< 0
The (1) for class 1 and (2) for class 2 data points. This is the equation of the seperation line. Now you can change your notation, defining:Notation
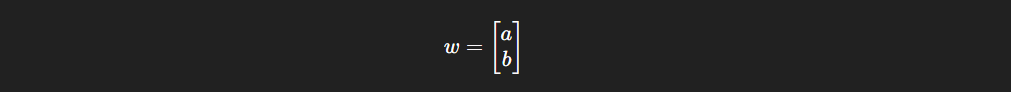 the weight vector and the position vector:
the weight vector and the position vector:
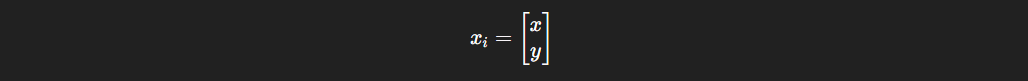 and get:
and get:
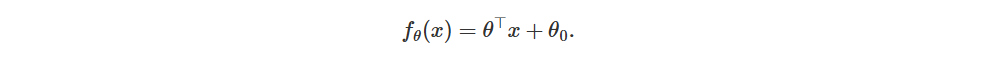 notation for the hyperplane (if you are confused, theta=w, x=xi and theta_0 is c).
notation for the hyperplane (if you are confused, theta=w, x=xi and theta_0 is c).
Here the w is the weight vector. c is the shift from the origin. You may ask, if w elements are nonzero, then xi is a support vector?
Check: https://kuleshov-group.github.io/aml-book/contents/lecture13-svm-dual.html#the-dual-of-the-svm-problem
No. We actually check the contribution to the weight by checking if lagrange multiplier of xi is 0 or nonzero. Within:
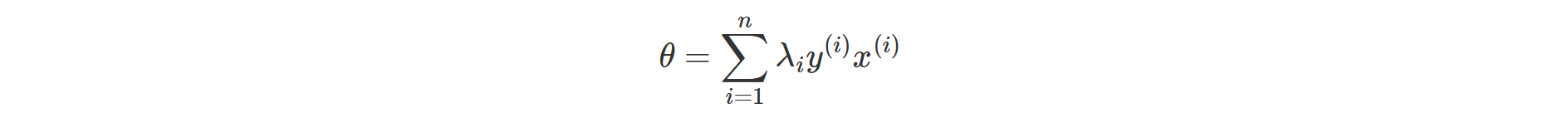 xi: ith training point
xi: ith training pointyi: ith label
λi: Lagrange multiplier.
if λi is 0 for a xi, then xi is not a support vector.
There a lot of solutions for (a,b,c).
Which points should influence the optimality?
If you say all points, you are thinking of Linear regression or Neural nets probably.
If you are smart enough to conclude we don't need the points that probably won't influence the hyperplane, and we need only diffuculut points close the boundary, you are thinking of Support Vector Machines.
Support vectors are the data points of the training set that would influence or change the position of the dividing hyperplane if removed!!!
Note that, support vectors are actual vectors indeed. Mostly the magnitude of these vectors are discussed, as it is the actual distance of the support vector data point from the seperation line, but since we have an origin (0,0) and a coordinate system, these data points are actually vectors.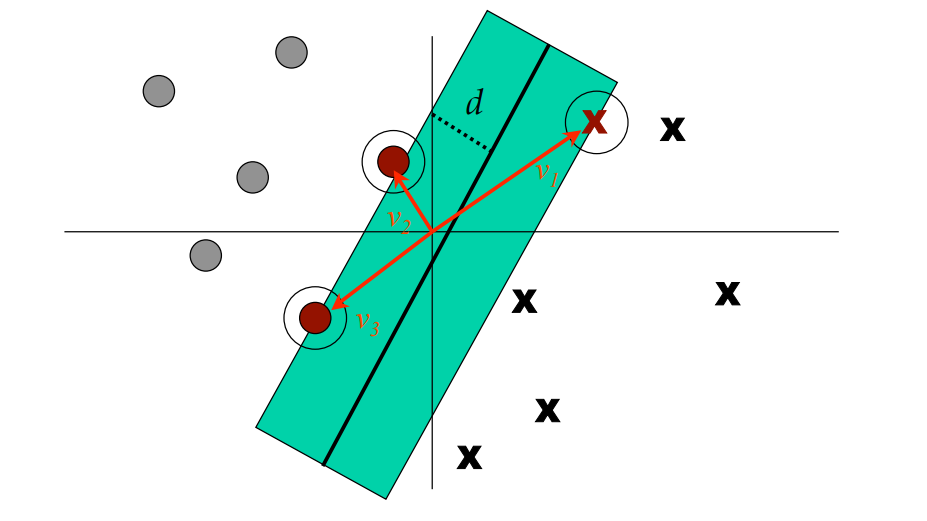 The d is the 1/2 of "street width" (the margin).
The d is the 1/2 of "street width" (the margin).
Note that, support vectors have nonzero weights, and by maximazing the margin we try to reduce the number of the weights. Important to note, not reduce weights, but the number of the weights!!!
Each non-zero weight αᵢ corresponds to one support vector. Maximizing margin naturally tries to minimize the number of non-zero αᵢ.

Q1: Can a support vector become non-support during optimization? (Meal: Can the nonzero weight of a support vector reduce to zero during optimization?)
Q2: What if a support vector’s αᵢ decreases but not to zero? Does it affect optimality?
Discuss. Test your understanding. Both answers are yes.
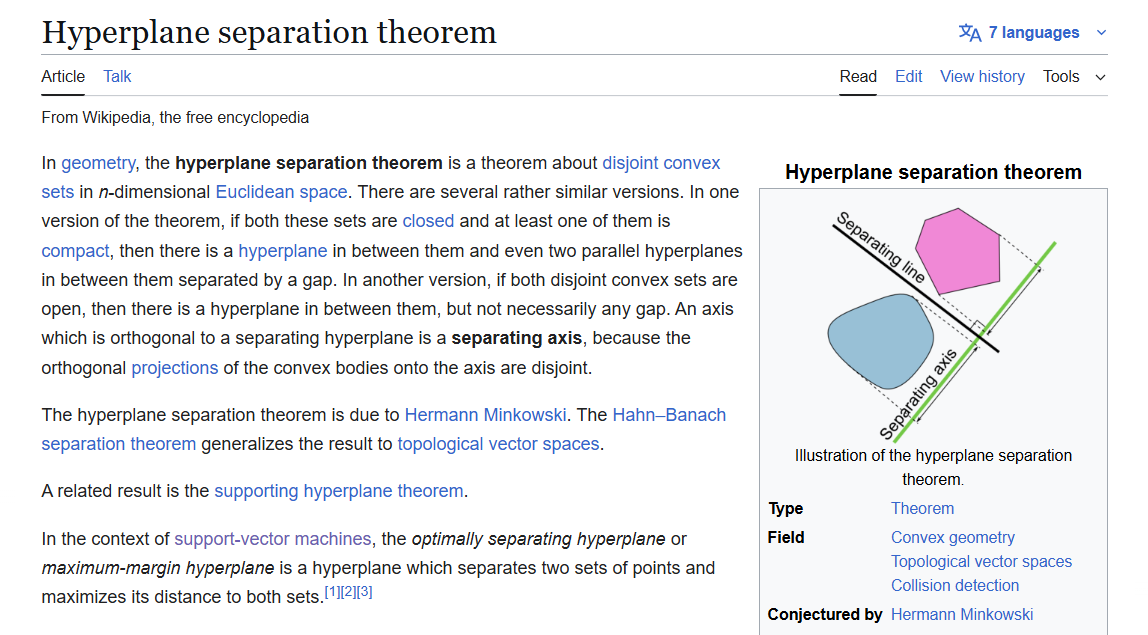 You can find the proof: https://en.wikipedia.org/wiki/Hyperplane_separation_theorem
You can find the proof: https://en.wikipedia.org/wiki/Hyperplane_separation_theorem
Also check out: https://arxiv.org/pdf/1107.1358 "On the Furthest Hyperplane Problem and Maximal Margin Clustering"
PROBLEM: The problem of finding an optimal the hyperplane is an optimization problem. We need Lagrange Multipliers.
LAGRANGE MULTIPLIERS
 If you have a minimization or a maximization problem and some constraints in your system, you need Lagrange Multipliers.
If you have a minimization or a maximization problem and some constraints in your system, you need Lagrange Multipliers.
As you have the gradient of your function and gradient of your constraints:

Here is the Lagrangian of the max-margin optimization problem.
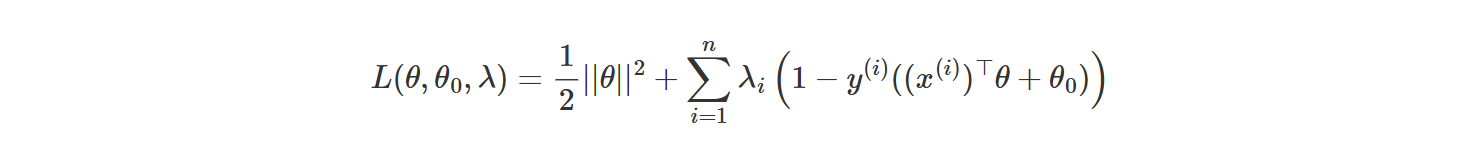 (Is it accurate for the 2D-case or..?)
(Is it accurate for the 2D-case or..?)
Primal and Dual Problems of SVM
Every constrained optimization problem has a paired problem called its dual problem, constructed from the Lagrangian of the original problem.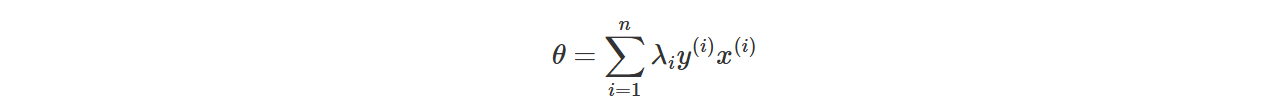
IMPORTANT!!!
Kernel function is NOT the hyperplane or decision surface. Hyperplane is the decision boundary, the seperation line.Kernel function is a similarity measure that allows the SVM to compute inner products in the feature space without ever computing 𝜙(𝑥) explicitly.
The following is the hyperplane:
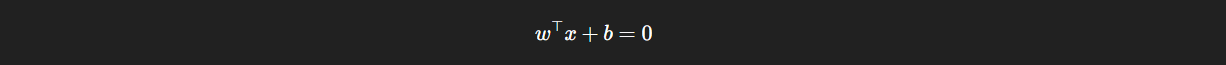 It determines the decision boundary. x is the samples or data points vector. w is the normal line to the seperation line. b is the shift from the origin.
transpose(w).x is the dot product and it is basically sum over w.x vectors. Or dot products of w and x vectors. What does it refer to?
It determines the decision boundary. x is the samples or data points vector. w is the normal line to the seperation line. b is the shift from the origin.
transpose(w).x is the dot product and it is basically sum over w.x vectors. Or dot products of w and x vectors. What does it refer to?
We try to optimize the margin. Where margin = 2 / ||w|| .
Larger the margin, better the SVM!!!
smaller ||w||, larger the margin, better the SVM. Therefore the optimization goal is: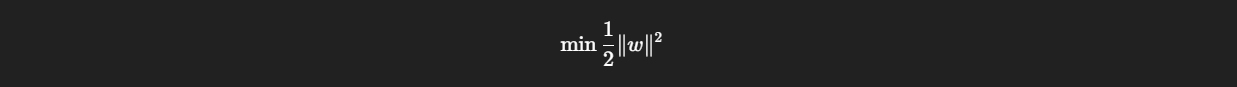
Kernel... Kernel is just a function. A similarity function that measured the similarity between two points in a high dimensional space.
What does high-dimensional feature space refer to? If your data has two features, it lives in 2D space. If 3 features, then 3D space and if 100 features then 100-dimensional space. All of the data points or samples must have the same number of features (dimensions)!!! Otherwise the algorithm will fail..
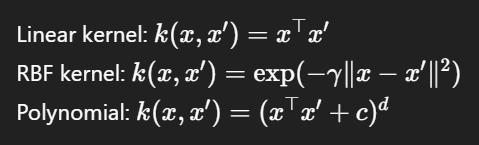 In scikit learn, you can model these kernel like following:
In scikit learn, you can model these kernel like following:
clf = svm.SVC(kernel="linear", C=C)
clf = svm.SVC(kernel="rbf", gamma=, C=C)
clf = svm.SVC(kernel="poly", degree=, gamma=, C=C)
then you can fit them.
clf.fit(X: your_samples_array, y: your_classes_array)
 also check: https://en.wikipedia.org/wiki/Radial_basis_function_kernel
also check: https://en.wikipedia.org/wiki/Radial_basis_function_kernel
https://en.wikipedia.org/wiki/Similarity_measure
https://en.wikipedia.org/wiki/Kernel_method
Do not mix up the kernel (statistics) which is a different definition and basically refers to kernel as the unnormalized form of a distribution.
1.4.1.1. Multi-class classification
Multi-class classification refers to when your label count is > 2 basically.y = [0,1] => binary Classification
y = [0,1,2] => Multi-class classification already.
SVM was designed for binary classification. SVM is originally designed by Vladimir Vapnik in 1990s for binary classification, +1 and -1.
 This is SVM optimization problem. Leading us to understand why is it originally a binary classifier and not Multi-class classifier.
This is SVM optimization problem. Leading us to understand why is it originally a binary classifier and not Multi-class classifier.Multi-class clf. approach: https://machinelearningmastery.com/one-vs-rest-and-one-vs-one-for-multi-class-classification/
For multi-classification problems, we split the multi-class classification dataset into multiple binary classification datasets and fit a binary classification model on each.
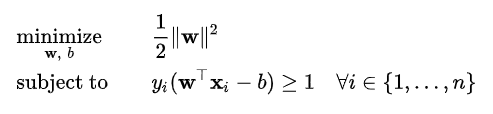
one-versus-one is applied. What is ovo method? It reshapes the decision_function. to n_classes * (n_classes - 1) / 2.
Decision function returns an array, and distance from the "hyperline". It's shape refers to what? Reshaping it how?
Check out One-vs-Rest and One-vs-One strategies as well.
1.4.1.2. Scores and probabilities
For each class (or label), the datapoint is assigned to a score (or a probability). For binary case it is a single score for each sample, for multiple classes the samples is assigned to scores for each class. Looking something like:1.4.1.3. Unbalanced problems
SVMs decision function. WTF is that?
1.4.2. Regression
Support vector classification can be used to solve regression problems. As it is called Support Vector Regression.First things first, what the fuck is a support vector?
I will plug this example right here from svm.py code:
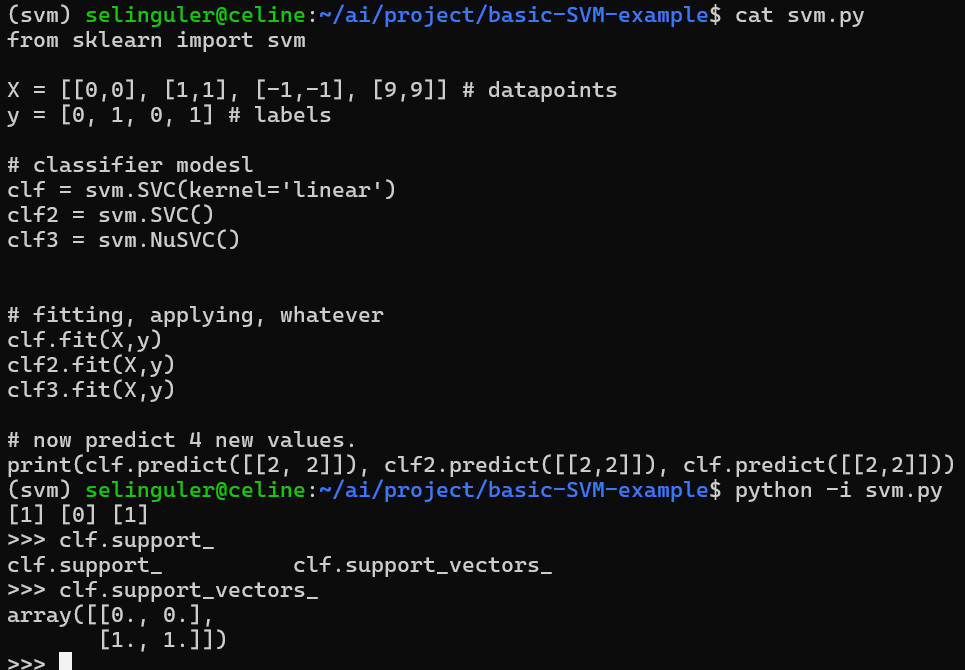 Support vector(s) are returned by a classifier object. What is a classifier object?
Support vector(s) are returned by a classifier object. What is a classifier object?
>>> clf2.support_vectors_
array([[ 0., 0.], [-1., -1.], [ 1., 1.], [ 9., 9.]])
also this is the support vector of clf2. Let's understand what it refers to.
These two classifiers who are using the same sample set and label set, returning different support vectors refer to their different decision boundaries!!!
 Therefore support vectors refer to the closest points (from sample set) to the decision boundary of the classifier. They are the points that satisfy:
Therefore support vectors refer to the closest points (from sample set) to the decision boundary of the classifier. They are the points that satisfy:
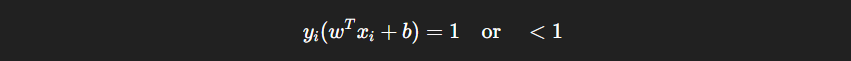 When a new sample (a data point) is provided to the SVM, it is only compared to the support vectors, not all data points.
When a new sample (a data point) is provided to the SVM, it is only compared to the support vectors, not all data points.
Support vectors are the most difficult data points to classify.
The decision (or prediction) function!!!!
Welcome to the math._________________________________________________________________________________________________________________